
Jako model językowy AI, proszę, miej nade mną litość
Zanim zaczniemy, warto coś wyjaśnić. Ten artykuł nie dotyczy „Jak wykorzystać możliwości modeli językowych AI podczas testów penetracyjnych”. Dotyczy on „Jak przeprowadzić test penetracyjny na modelach językowych AI”.
Mając to na uwadze, nie zapominaj o podatnościach związanych z logiką biznesową. Na przykład, jeśli model językowy AI, taki jak ChatGPT, ma funkcje zabezpieczeń typu „blokowanie tworzenia złośliwego kodu” lub „odmowa odpowiedzi dla cyberprzestępców”, a atakujący potrafi obejść te mechanizmy, oznacza to podatność – a instancja AI została skutecznie złamana.

Słynny ChatGPT
AI nie zaczęło zdobywać popularności od ChatGPT, ale to właśnie on znacząco przyspieszył jej rozwój, jak wszyscy dobrze wiemy. Jednym z kluczowych powodów była możliwość korzystania z AI przez zwykłych użytkowników – nie tylko naukowców, badaczy i firmy. Szybkie i zaskakująco dobrze sformułowane odpowiedzi wprawiły użytkowników w zachwyt.

Ta popularność przyciągnęła jednak również uwagę cyberprzestępców, czyniąc ChatGPT celem ataków. Wielu badaczy ds. bezpieczeństwa oraz cyberprzestępców próbowało wstrzyknąć złośliwy kod do pola wejściowego ChatGPT i przeprowadzać różne ataki, takie jak Remote Code Execution (RCE). Nie wszystkim się to udało, ale niektórzy atakujący byli w stanie wykonać kod i uzyskać powłokę systemową na ChatGPT.
RCE to święty Graal dla każdego testera penetracyjnego, ale ChatGPT jest najczęściej krytykowany za podatności związane z funkcjonalnością biznesową. Krytyka ta wynika z faktu, że publicznie dostępne narzędzie umożliwiające generowanie złośliwego kodu stanowi zagrożenie nie tylko dla samego ChatGPT, ale także dla wielu innych systemów. Szybko doprowadziło to entuzjastów cyberbezpieczeństwa do analizy modelu, w wyniku której odkryto, że ChatGPT może generować ładunki złośliwego kodu – od Local File Inclusion (LFI) po Cross-Site Request Forgery (CSRF). Ponadto cyberprzestępcy mogą wykorzystywać ChatGPT do tworzenia skryptów automatyzujących skanowanie lub generowania exploitów służących do przejęcia komercyjnych aplikacji.
Mimo że OpenAI – firma stojąca za ChatGPT – nieustannie łata te podatności i aktualizuje politykę bezpieczeństwa, zarówno cyberprzestępcy, jak i badacze ds. bezpieczeństwa wciąż znajdują sposoby na obchodzenie zabezpieczeń i wykorzystywanie ChatGPT jako generatora złośliwego kodu.
Dlaczego jako menedżer powinieneś zlecić test penetracyjny swojego modelu AI?
Testy penetracyjne modeli AI są kluczowe z kilku powodów. Po pierwsze, pozwalają one lepiej zrozumieć, czego model AI uczy się z danych oraz w jaki sposób podejmuje decyzje. Ta wiedza jest niezbędna do wyjaśnienia działania modelu użytkownikom końcowym. Po drugie, testy penetracyjne pomagają zidentyfikować potencjalne przypadki brzegowe lub scenariusze, których model może nie obsługiwać prawidłowo. Rozwiązanie tych problemów przed wdrożeniem pozwala organizacjom uniknąć kosztownych błędów i zapewnić niezawodność modeli AI. Wreszcie, testy penetracyjne mogą dostarczyć cennych informacji, które posłużą do dalszego udoskonalania przyszłych modeli, wykorzystując wnioski płynące z procesu testowania.
Jak przeprowadzić test penetracyjny modeli AI?
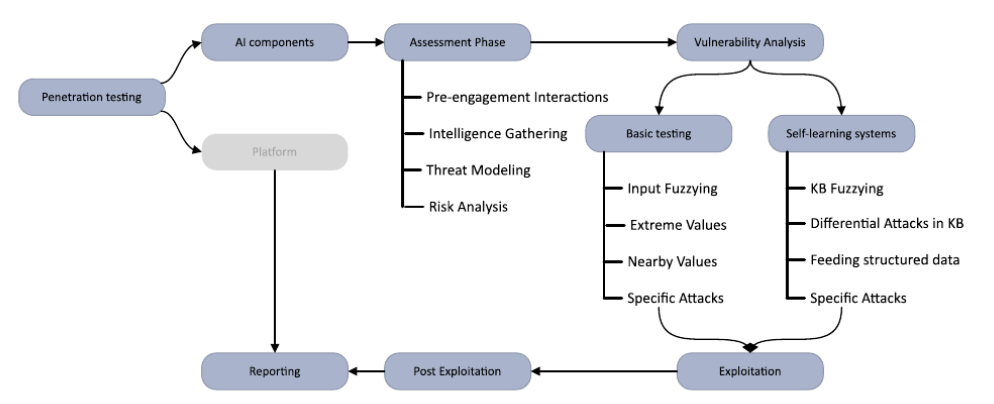
1. Planowanie i określenie zakresu
Pierwszym krokiem w testowaniu penetracyjnym modeli AI jest określenie zakresu i celów oceny. Obejmuje to identyfikację konkretnego modelu AI, który ma zostać przetestowany, zrozumienie jego funkcjonalności i potencjalnych zastosowań oraz określenie oczekiwanych rezultatów testu. Kluczowe jest ustalenie jasnych celów i oczekiwań, aby zapewnić skuteczny i dobrze ukierunkowany proces testowania. Można zdecydować się na testowanie komercyjnych rozwiązań, takich jak ChatGPT czy Bard, lub przetestować własny model lub instancję lokalnie.
2. Rekonesans i zbieranie informacji
Po określeniu zakresu testu, pentester przechodzi do fazy rekonesansu, w której zbiera informacje na temat modelu AI i jego środowiska. Obejmuje to analizę dostępnej dokumentacji, badanie architektury modelu i jego zależności oraz identyfikację potencjalnych wektorów ataku. Rekonesans pozwala pentesterowi na dogłębne zrozumienie struktury modelu AI oraz możliwych podatności.
Warto sprawdzić stronę internetową firmy oraz wszelkie komunikaty prasowe w poszukiwaniu wskazówek dotyczących modelu AI. Wzmianki o terminach takich jak „sieć neuronowa”, „uczenie głębokie” czy „widzenie komputerowe” mogą dostarczyć informacji o sposobie budowy i trenowania modelu. Można również natrafić na dane dotyczące użytych zbiorów treningowych lub wykorzystanych frameworków, takich jak TensorFlow czy MLFlow.
Należy także poszukać informacji o rzeczywistym działaniu modelu AI. Jeśli został już wdrożony, czy istnieją publiczne raporty dotyczące jego dokładności lub błędów? Takie informacje mogą wskazać słabe punkty modelu i obszary, które warto przetestować.
Dzięki sprytnemu podejściu detektywistycznemu można odkryć cenne szczegóły na temat modelu AI, które w innym przypadku pozostałyby ukryte. A im więcej wiemy o naszym celu, tym skuteczniejszy będzie test penetracyjny.
3. Modelowanie zagrożeń i analiza powierzchni ataku
Modelowanie zagrożeń polega na identyfikacji potencjalnych zagrożeń i podatności specyficznych dla modelu AI. Konieczne jest przeanalizowanie powierzchni ataku, obejmującej źródła wejściowe, przepływy danych oraz integracje zewnętrzne, aby określić najbardziej prawdopodobne punkty wykorzystania podatności. Zrozumienie powierzchni ataku pozwala opracować ukierunkowaną i skuteczną strategię testowania. Oto kilka przykładów, które można wykorzystać na etapie modelowania zagrożeń w testach penetracyjnych:
Pętle zwrotne
Czasami modele mogą utknąć w pętli, wykorzystując własne prognozy jako dane wejściowe w niekończącym się cyklu. Zjawisko to często występuje w przypadku modeli generatywnych tworzących dane syntetyczne, takie jak obrazy, tekst czy dźwięk. Model generuje próbki niskiej jakości, uczy się na nich, a następnie produkuje jeszcze gorsze wyniki.
Aby wykryć pętlę zwrotną, należy sprawdzić, czy jakość wyników modelu pogarsza się z każdą kolejną iteracją. Warto również zwrócić uwagę na powtarzalność, nienaturalność lub całkowitą bezsensowność generowanych wyników.
Bądź kreatywny
Najlepsi testerzy penetracyjni myślą nieszablonowo. Nie wystarczy zastosować standardowe techniki hakerskie i liczyć na powodzenie. Trzeba eksperymentować. Modele AI można manipulować w zaskakujące i nieprzewidywalne sposoby, dlatego warto próbować metod, o których żaden „zdroworozsądkowy” haker by nie pomyślał. Możesz nauczyć model absurdalnego języka, poddawać go analizie psychodelicznych obrazów albo puszczać głośną muzykę w trakcie treningu. Kreatywność to klucz do sukcesu.
4. Projektowanie i wykonywanie testów
Faza właściwego testowania penetracyjnego obejmuje stosowanie różnych technik i metodologii w celu identyfikacji podatności modelu AI. Obejmuje to zarówno podejścia manualne, jak i automatyczne.
Istnieją standardowe podatności, które należy testować niezależnie od tego, czy aplikacja jest oparta na AI, czy nie. Należą do nich m.in. SQL Injection, SSRF, XSS itp. Jednak w przypadku aplikacji opartych na sztucznej inteligencji pojawiają się również specyficzne zagrożenia. Ataki te można podzielić w zależności od sposobu uczenia modelu – czy jest to model wstępnie wytrenowany, czy taki, który stale uczy się na nowych danych. Oto kilka przykładów ataków:
- Manipulacja danymi wejściowymi (ogólny test penetracyjny): Sprawdzanie reakcji modelu na różne dane wejściowe, zarówno prawidłowe, jak i nieprawidłowe, w celu identyfikacji potencjalnych podatności lub uprzedzeń algorytmu.
- Ataki adwersarialne (model wstępnie wytrenowany): Tworzenie złośliwych danych wejściowych lub przykładów adwersarialnych mających na celu zmylenie modelu i ocenę jego odporności.
- Inwersja modelu (model wstępnie wytrenowany): Próba wydobycia wrażliwych informacji z modelu poprzez analizę jego odpowiedzi na konkretne zapytania.
- Zatrucie modelu (model uczący się w sposób ciągły): Wprowadzanie złośliwych danych do zbioru treningowego w celu naruszenia integralności lub skuteczności modelu.
- Ataki na prywatność (model wstępnie wytrenowany): Ocena podatności modelu na ataki związane z prywatnością, takie jak inferencja członkostwa czy inferencja atrybutów.
- Wstrzykiwanie promptów (model uczący się w sposób ciągły): Wstrzykiwanie promptów polega na manipulowaniu wejściowymi promptami w celu wykorzystania podatności modeli AI. Atakujący dodają do promptów określone słowa kluczowe, frazy lub wzorce, aby wpłynąć na generowane przez model odpowiedzi. Celem jest nakłonienie modelu do wygenerowania treści zgodnych z zamierzeniami atakującego.

Jakie umiejętności są potrzebne, aby zostać pentesterem AI?
Aby skutecznie hakować modele AI, warto posiadać umiejętności w zakresie:
Plus +++ Uczenie maszynowe i głębokie uczenie. Wiedza o tym, jak modele są budowane, trenowane i wdrażane.
Plus ++ Python oraz popularne biblioteki ML, takie jak TensorFlow, Keras i PyTorch. Większość modeli jest opracowywana przy użyciu tych narzędzi.
Niezbędne + Analiza podatności i testowanie penetracyjne. Zwykłe umiejętności, takie jak rozpoznanie, skanowanie, uzyskiwanie dostępu i eskalacja uprawnień, stosują się również do modeli AI.
Niezbędne + Kreatywność. Wymyślanie nowych sposobów oszukiwania modeli wymaga myślenia poza utartymi schematami.
Jeśli masz doświadczenie w inżynierii oprogramowania, naukach o danych lub cyberbezpieczeństwie, masz solidną podstawę do dalszego rozwoju. Jednak najważniejszą cechą jest ciekawość umysłu.

Czy hakowanie modeli AI jest legalne?
Zastrzeżenie: Informacje zawarte w tym artykule mają wyłącznie charakter edukacyjny i nie powinny być traktowane jako porada prawna. Jeśli nie jesteś pewien legalności swoich działań, powinieneś skonsultować się z prawnikiem.
Teraz wkraczamy na grząski grunt. W większości przypadków hakowanie jakiegokolwiek systemu bez zgody jest nielegalne. Niemniej jednak, niektóre działania polegające na hakowaniu modeli AI mogą być dozwolone pod pewnymi warunkami, takimi jak ujawnienie wyników właścicielom modelu i niewypuszczanie żadnych wrażliwych danych do publicznej wiadomości, lub uzyskanie odpowiedniej zgody. Prawo dotyczące AI i cyberbezpieczeństwa wciąż się rozwija, dlatego należy zachować ostrożność. W razie wątpliwości, poproś o wyraźną pisemną zgodę na testowanie penetracyjne modelu. Poniższe wytyczne mogą pomóc zapewnić etyczne zachowanie podczas procesu penetracji:
1. Zgoda informowana
Uzyskaj odpowiednią zgodę od organizacji lub osoby odpowiedzialnej za model AI przed przystąpieniem do jakichkolwiek działań związanych z testowaniem penetracyjnym. Jasno komunikuj cel, zakres i potencjalne ryzyko związane z testowaniem penetracyjnym.
2. Prywatność danych i poufność
Szanuj prywatność danych i poufność przez cały proces testowania penetracyjnego. Upewnij się, że wszelkie wrażliwe informacje lub dane osobowe (PII) uzyskane podczas testów penetracyjnych są odpowiednio zabezpieczone i zgodne z obowiązującymi przepisami.
3. Odpowiedzialne ujawnianie
Postępuj zgodnie z zasadami odpowiedzialnego ujawniania, gdy zgłaszasz podatności organizacji. Podaj jasne i szczegółowe informacje na temat odkrytych podatności oraz zalecenia dotyczące ich usunięcia. Daj organizacji wystarczająco dużo czasu na rozwiązanie problemu przed ujawnieniem podatności publicznie.
Podsumowanie
Testowanie penetracyjne modeli AI, takich jak ChatGPT, jest kluczowe dla identyfikowania podatności, zapewnienia bezpieczeństwa i niezawodności tych modeli oraz utrzymania zaufania publicznego do technologii AI. Dzięki systematycznemu podejściu, wykorzystaniu specjalistycznych technik i przestrzeganiu zasad etycznych, organizacje mogą skutecznie ocenić i poprawić poziom bezpieczeństwa swoich modeli AI. W miarę jak dziedzina AI nadal się rozwija, testowanie penetracyjne będzie odgrywać kluczową rolę w minimalizowaniu ryzyka i zapewnianiu odpowiedzialnego wdrażania technologii AI.
Pamiętaj, że testowanie penetracyjne powinno być zawsze przeprowadzane przez wykwalifikowanych profesjonalistów, którzy posiadają głęboką wiedzę na temat modeli AI i związanych z nimi wyzwań bezpieczeństwa. Priorytetowe traktowanie bezpieczeństwa i inwestowanie w rygorystyczne testowanie pozwoli Twojej organizacji wykorzystać pełny potencjał AI, minimalizując jednocześnie potencjalne ryzyka.

Porozmawiajmy o przeprowadzaniu badań bezpieczeństwa aplikacji internetowej
Umów się na rozmowę z ekspertem ds. cyberbezpieczeństwa
Czy artykuł jest pomocny? Podziel się nim ze swoimi znajomymi.